AI Infrastructure
Open Source Analysis
HyperCLOVA X SEED 분석 및 환경 구축
"사내 분석 요청에 따른 오픈소스 모델 HyperCLOVA X SEED 구동 및 기술 검토를 위한 환경 구축"
구축 배경
사내에서 네이버 클라우드가 오픈소스로 공개한 HyperCLOVA X SEED 모델에 대한 기술 분석 요청을 받아 구축하였습니다. 보고 전 실제 모델의 동작 확인 및 분석을 위해
Hugging Face 를 분석, 개인 서버에 구동 환경을 구축하여 기능을 검증했습니다.
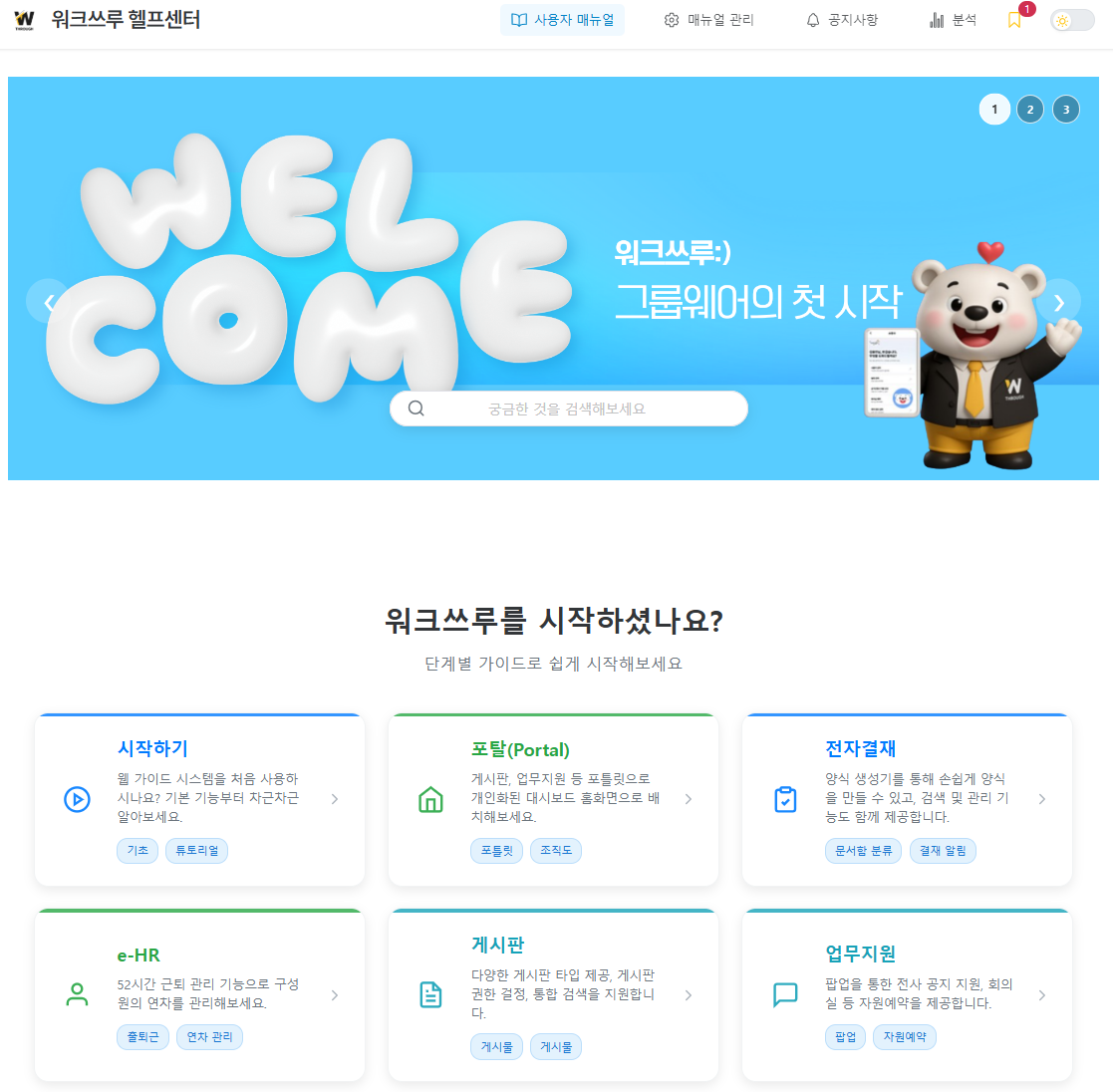
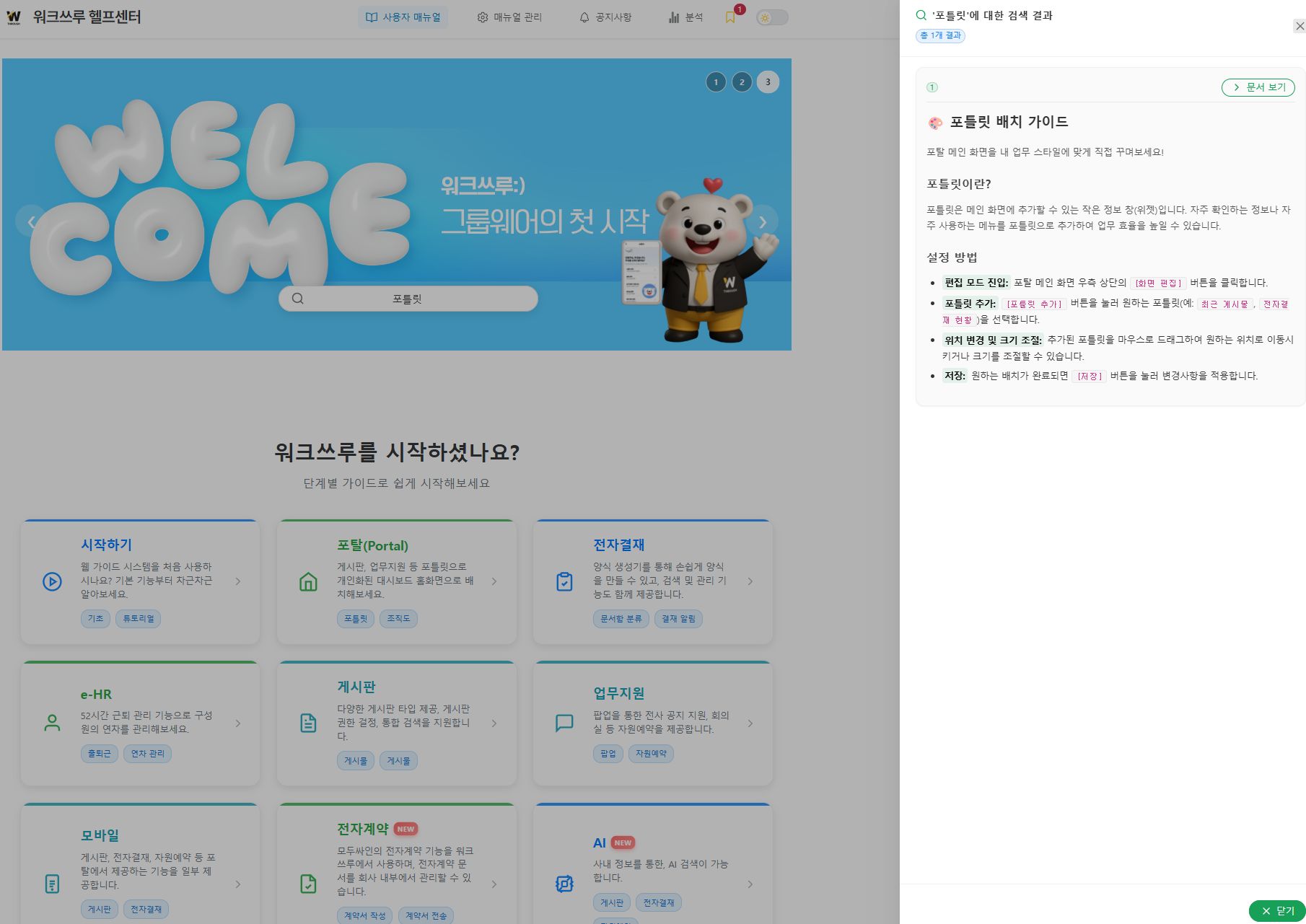
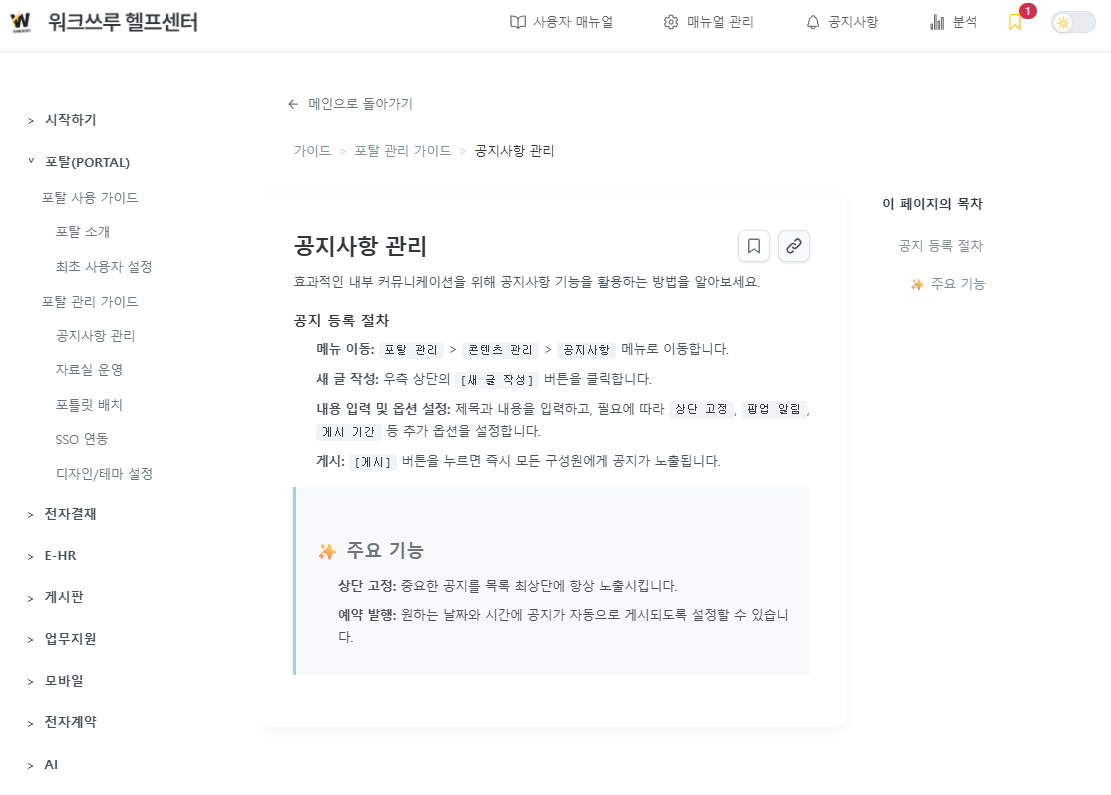
🎯 주요 수행 내용
- 📋 오픈소스 모델 분석: SEED 모델(0.5B, 1.5B)의 파라미터 사이즈별 실제 리소스 사용량 및 추론 결과 확인
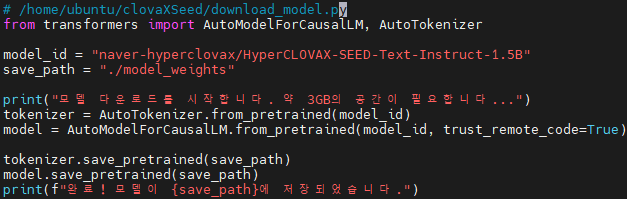
- 📦 Hugging Face 연동: Clova X Seed 공식 저장소를 이용하여 Seed 모델 구축
- 🛡️ Python venv 독립성 확보: 시스템 환경과의 충돌 방지 및 보고용 분석 환경의 독립성 유지를 위한 가상환경 구축
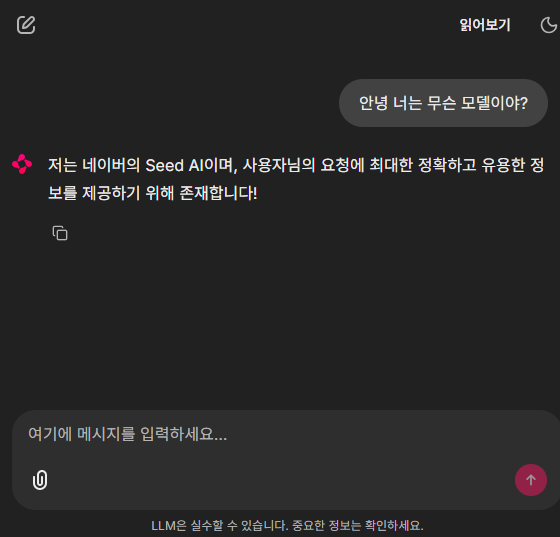
- 🖥️ Chainlit 기반 테스트 UI 구현: 오픈소스 UI 프레임워크인 Chainlit을 연동하여 분석 결과를 시각적으로 확인하고 모델 응답을 실시간으로 검증
기술 분석 개요 (HyperCLOVA X SEED)
HyperCLOVA X SEED는 네이버 클라우드에서 오픈소스로 공개한 효율성 중심의 모델 시리즈입니다. 사내 분석 요청에 맞춰 0.5B, 1.5B 모델이 실제 리소스 환경에서 어떻게 동작하는지 확인하고, Chainlit을 사용하여 인터페이스 환경에서의 활용성을 분석했습니다.
분석 환경 구축 전략
기존 시스템 및 타 프로젝트와의 환경 충돌을 방지하고 시스템 안정성을 확보하기 위해 Python venv를 통한 의존성 격리를 적용했습니다. 특히 분석용 UI로 Chainlit을 도입하여, 모델의 성능과 응답 품질을 효율적으로 검증할 수 있었습니다.